
 MENU
MENU 

Fourteen papers by CSE researchers presented at NeurIPS 2023

CSE researchers are presenting a total of 14 papers at the 2023 Conference and Workshop on Neural Information Processing Systems, also known as NeurIPS. First held in 1986, NeurIPS is a leading international conference in the field of artificial intelligence, bringing together experts from across the globe to present the latest findings in the areas of machine learning and computational neuroscience. This year’s conference is being held in New Orleans, LA, from December 10-16, 2023.
Eighteen CSE faculty and students are presenting new research and innovations at the conference. Their papers cover a range of topics related to neural networks and machine learning, including the development of an enhanced diffusion model for image manipulation, an automatic approach for generating captions for 3D objects, a novel deep learning framework for MRI imaging, and more.
The papers appearing at the conference are as follows, with the names of CSE authors in bold:
CycleNet: Rethinking Cycle Consistency in Text-Guided Diffusion for Image Manipulation
Sihan Xu, Ziqiao Ma, Yidong Huang, Honglak Lee, Joyce Chai
Abstract: Diffusion models (DMs) have enabled breakthroughs in image synthesis tasks but lack an intuitive interface for consistent image-to-image (I2I) translation. Various methods have been explored to address this issue, including mask-based methods, attention-based methods, and image-conditioning. However, it remains a critical challenge to enable unpaired I2I translation with pre-trained DMs while maintaining satisfying consistency. This paper introduces Cyclenet, a novel but simple method that incorporates cycle consistency into DMs to regularize image manipulation. We validate Cyclenet on unpaired I2I tasks of different granularities. Besides the scene and object level translation, we additionally contribute a multi-domain I2I translation dataset to study the physical state changes of objects. Our empirical studies show that Cyclenet is superior in translation consistency and quality, and can generate high-quality images for out-of-domain distributions with a simple change of the textual prompt. Cyclenet is a practical framework, which is robust even with very limited training data (around 2k) and requires minimal computational resources (1 GPU) to train. Project homepage: https://cyclenetweb.github.io/

Projection Regret: Reducing Background Bias for Novelty Detection via Diffusion Models
Sungik Choi, Hankook Lee, Honglak Lee, Moontae Lee
Abstract: Novelty detection is a fundamental task of machine learning which aims to detect abnormal (i.e. out-of-distribution (OOD)) samples. Since diffusion models have recently emerged as the de facto standard generative framework with surprising generation results, novelty detection via diffusion models has also gained much attention. Recent methods have mainly utilized the reconstruction property of in-distribution samples. However, they often suffer from detecting OOD samples that share similar background information to the in-distribution data. Based on our observation that diffusion models can \emph{project} any sample to an in-distribution sample with similar background information, we propose \emph{Projection Regret (PR)}, an efficient novelty detection method that mitigates the bias of non-semantic information. To be specific, PR computes the perceptual distance between the test image and its diffusion-based projection to detect abnormality. Since the perceptual distance often fails to capture semantic changes when the background information is dominant, we cancel out the background bias by comparing it against recursive projections. Extensive experiments demonstrate that PR outperforms the prior art of generative-model-based novelty detection methods by a significant margin.
Scalable 3D Captioning with Pretrained Models
Tiange Luo, Chris Rockwell, Honglak Lee, Justin Johnson
Abstract: We introduce Cap3D, an automatic approach for generating descriptive text for 3D objects. This approach utilizes pretrained models from image captioning, image-text alignment, and LLM to consolidate captions from multiple views of a 3D asset, completely side-stepping the time-consuming and costly process of manual annotation. We apply Cap3D to the recently introduced large-scale 3D dataset, Objaverse, resulting in 660k 3D-text pairs. Our evaluation, conducted using 41k human annotations from the same dataset, demonstrates that Cap3D surpasses human-authored descriptions in terms of quality, cost, and speed. Through effective prompt engineering, Cap3D rivals human performance in generating geometric descriptions on 17k collected annotations from the ABO dataset. Finally, we finetune Text-to-3D models on Cap3D and human captions, and show Cap3D outperforms; and benchmark the SOTA including Point-E, Shape-E, and DreamFusion.

SafeDICE: Offline Safe Imitation Learning with Non-Preferred Demonstrations
Youngsoo Jang, Geon-Hyeong Kim, Jongmin Lee, Sungryull Sohn, Byoungjip Kim, Honglak Lee, Moontae Lee
We consider offline safe imitation learning (IL), where the agent aims to learn the safe policy that mimics preferred behavior while avoiding non-preferred behavior from non-preferred demonstrations and unlabeled demonstrations. This problem setting corresponds to various real-world scenarios, where satisfying safety constraints is more important than maximizing the expected return. However, it is very challenging to learn the policy to avoid constraint-violating (i.e. non-preferred) behavior, as opposed to standard imitation learning which learns the policy to mimic given demonstrations. In this paper, we present a hyperparameter-free offline safe IL algorithm, SafeDICE, that learns safe policy by leveraging the non-preferred demonstrations in the space of stationary distributions. Our algorithm directly estimates the stationary distribution corrections of the policy that imitate the demonstrations excluding the non-preferred behavior. In the experiments, we demonstrate that our algorithm learns a more safe policy that satisfies the cost constraint without degrading the reward performance, compared to baseline algorithms.
Combining Behaviors with the Successor Features Keyboard
Wilka Carvalho, Andre Saraiva, Angelos Filos, Andrew Lampinen, Loic Matthey, Richard L Lewis, Honglak Lee, Satinder Singh, Danilo Jimenez Rezende, Daniel Zoran

Abstract: The Option Keyboard (OK) was recently proposed as a method for transferring behavioral knowledge across tasks. OK transfers knowledge by adaptively combining subsets of known behaviors using Successor Features (SFs) and Generalized Policy Improvement (GPI). However, it relies on hand-designed state-features and task encodings which are cumbersome to design for every new environment. In this work, we propose the “Successor Features Keyboard” (SFK), which enables transfer with discovered state-features and task encodings. To enable discovery, we propose the “Categorical Successor Feature Approximator” (CSFA), a novel learning algorithm for estimating SFs while jointly discovering state-features and task encodings. With SFK and CSFA, we achieve the first demonstration of transfer with SFs in a challenging 3D environment where all the necessary representations are discovered. We first compare CSFA against other methods for approximating SFs and show that only CSFA discovers representations compatible with SF&GPI at this scale. We then compare SFK against transfer learning baselines and show that it transfers most quickly to long-horizon tasks.
Guide Your Agent with Adaptive Multimodal Rewards
Changyeon Kim, Younggyo Seo, Hao Liu, Lisa Lee, Jinwoo Shin, Honglak Lee, Kimin Lee
Abstract: Developing an agent capable of adapting to unseen environments remains a difficult challenge in imitation learning. This work presents Adaptive Return-conditioned Policy (ARP), an efficient framework designed to enhance the agent’s generalization ability using natural language task descriptions and pre-trained multimodal encoders. Our key idea is to calculate a similarity between visual observations and natural language instructions in the pre-trained multimodal embedding space (such as CLIP) and use it as a reward signal. We then train a return-conditioned policy using expert demonstrations labeled with multimodal rewards. Because the multimodal rewards provide adaptive signals at each timestep, our ARP effectively mitigates the goal misgeneralization. This results in superior generalization performances even when faced with unseen text instructions, compared to existing text-conditioned policies. To improve the quality of rewards, we also introduce a fine-tuning method for pre-trained multimodal encoders, further enhancing the performance. Video demonstrations and source code are available on the project website.
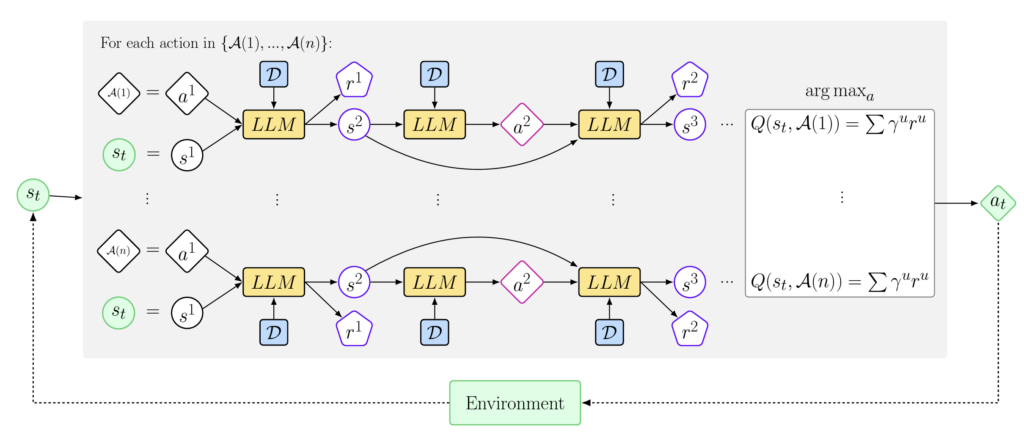
Large Language Models can Implement Policy Iteration
Ethan Brooks, Logan Walls, Richard L Lewis, Satinder Singh
Abstract: This work presents In-Context Policy Iteration, an algorithm for performing Reinforcement Learning (RL), in-context, using foundation models. While the application of foundation models to RL has received considerable attention, most approaches rely on either (1) the curation of expert demonstrations (either through manual design or task-specific pretraining) or (2) adaptation to the task of interest using gradient methods (either fine-tuning or training of adapter layers). Both of these techniques have drawbacks. Collecting demonstrations is labor-intensive, and algorithms that rely on them do not outperform the experts from which the demonstrations were derived. All gradient techniques are inherently slow, sacrificing the “few-shot” quality that made in-context learning attractive to begin with. In this work, we present an algorithm, ICPI, that learns to perform RL tasks without expert demonstrations or gradients. Instead we present a policy-iteration method in which the prompt content is the entire locus of learning. ICPI iteratively updates the contents of the prompt from which it derives its policy through trial-and-error interaction with an RL environment. In order to eliminate the role of in-weights learning (on which approaches like Decision Transformer rely heavily), we demonstrate our algorithm using Codex, a language model with no prior knowledge of the domains on which we evaluate it.
Structured State Space Models for In-Context Reinforcement Learning
Chris Lu, Yannick Schroecker, Albert Gu, Emilio Parisotto, Jakob Foerster, Satinder Singh, Feryal Behbahani
Abstract: Structured state space sequence (S4) models have recently achieved state-of-the-art performance on long-range sequence modeling tasks. These models also have fast inference speeds and parallelisable training, making them potentially useful in many reinforcement learning settings. We propose a modification to a variant of S4 that enables us to initialise and reset the hidden state in parallel, allowing us to tackle reinforcement learning tasks. We show that our modified architecture runs asymptotically faster than Transformers in sequence length and performs better than RNN’s on a simple memory-based task. We evaluate our modified architecture on a set of partially-observable environments and find that, in practice, our model outperforms RNN’s while also running over five times faster. Then, by leveraging the model’s ability to handle long-range sequences, we achieve strong performance on a challenging meta-learning task in which the agent is given a randomly-sampled continuous control environment, combined with a randomly-sampled linear projection of the environment’s observations and actions. Furthermore, we show the resulting model can adapt to out-of-distribution held-out tasks. Overall, the results presented in this paper show that structured state space models are fast and performant for in-context reinforcement learning tasks. Code for this project is available on GitHub.
Sebastian Flennerhag, Tom Zahavy, Brendan O’Donoghue, Hado van Hasselt, András György, Satinder Singh
Abstract: We study the connection between gradient-based meta-learning and convex op-timisation. We observe that gradient descent with momentum is a special case of meta-gradients, and building on recent results in optimisation, we prove convergence rates for meta-learning in the single task setting. While a meta-learned update rule can yield faster convergence up to constant factor, it is not sufficient for acceleration. Instead, some form of optimism is required. We show that optimism in meta-learning can be captured through Bootstrapped Meta-Gradients (Flennerhag et al., 2022), providing deeper insight into its underlying mechanics.
A Definition of Continual Reinforcement Learning
David Abel, Andre Barreto, Benjamin Van Roy, Doina Precup, Hado van Hasselt, Satinder Singh
Abstract: In a standard view of the reinforcement learning problem, an agent’s goal is to efficiently identify a policy that maximizes long-term reward. However, this perspective is based on a restricted view of learning as finding a solution, rather than treating learning as endless adaptation. In contrast, continual reinforcement learning refers to the setting in which the best agents never stop learning. Despite the importance of continual reinforcement learning, the community lacks a simple definition of the problem that highlights its commitments and makes its primary concepts precise and clear. To this end, this paper is dedicated to carefully defining the continual reinforcement learning problem. We formalize the notion of agents that “never stop learning” through a new mathematical language for analyzing and cataloging agents. Using this new language, we define a continual learning agent as one that can be understood as carrying out an implicit search process indefinitely, and continual reinforcement learning as the setting in which the best agents are all continual learning agents. We provide two motivating examples, illustrating that traditional views of multi-task reinforcement learning and continual supervised learning are special cases of our definition. Collectively, these definitions and perspectives formalize many intuitive concepts at the heart of learning, and open new research pathways surrounding continual learning agents.
Counterfactual-Augmented Importance Sampling for Semi-Offline Policy Evaluation
Shengpu Tang, Jenna Wiens
Abstract: In applying reinforcement learning (RL) to high-stakes domains, quantitative and qualitative evaluation using observational data can help practitioners understand the generalization performance of new policies. However, this type of off-policy evaluation (OPE) is inherently limited since offline data may not reflect the distribution shifts resulting from the application of new policies. On the other hand, online evaluation by collecting rollouts according to the new policy is often infeasible, as deploying new policies in these domains can be unsafe. In this work, we propose a semi-offline evaluation framework as an intermediate step between offline and online evaluation, where human users provide annotations of unobserved counterfactual trajectories. While tempting to simply augment existing data with such annotations, we show that this naive approach can lead to biased results. Instead, we design a new family of OPE estimators based on importance sampling (IS) and a novel weighting scheme that incorporates counterfactual annotations without introducing additional bias. We analyze the theoretical properties of our approach, showing its potential to reduce both bias and variance compared to standard IS estimators. Our analyses reveal important practical considerations for handling biased, noisy, or missing annotations. In a series of proof-of-concept experiments involving bandits and a healthcare-inspired simulator, we demonstrate that our approach outperforms purely offline IS estimators and is robust to imperfect annotations. Our framework, combined with principled human-centered design of annotation solicitation, can enable the application of RL in high-stakes domains.
ResoNet: Noise-Trained Physics-Informed MRI Off-Resonance Correction
Alfredo De Goyeneche Macaya, Shreya Ramachandran, Ke Wang, Ekin Karasan, Joseph Y. Cheng, Stella X. Yu, Michael Lustig
Abstract: Magnetic Resonance Imaging (MRI) is a powerful medical imaging modality that offers diagnostic information without harmful ionizing radiation. Unlike optical imaging, MRI sequentially samples the spatial Fourier domain (k-space) of the image. Measurements are collected in multiple shots, or readouts, and in each shot, data along a smooth trajectory is sampled. Conventional MRI data acquisition relies on sampling k-space row-by-row in short intervals, which is slow and inefficient. More efficient, non-Cartesian sampling trajectories (e.g., Spirals) use longer data readout intervals, but are more susceptible to magnetic field inhomogeneities, leading to off-resonance artifacts. Spiral trajectories cause off-resonance blurring in the image, and the mathematics of this blurring resembles that of optical blurring, where magnetic field variation corresponds to depth and readout duration to aperture size. Off-resonance blurring is a system issue with a physics-based, accurate forward model. We present a physics-informed deep learning framework for off-resonance correction in MRI, which is trained exclusively on synthetic, noise-like data with representative marginal statistics. Our approach allows for fat/water separation and is compatible with parallel imaging acceleration. Through end-to-end training using synthetic randomized data (i.e., noise-like images, coil sensitivities, field maps), we train the network to reverse off-resonance effects across diverse anatomies and contrasts without retraining. We demonstrate the effectiveness of our approach through results on phantom and in-vivo data. This work has the potential to facilitate the clinical adoption of non-Cartesian sampling trajectories, enabling efficient, rapid, and motion-robust MRI scans. Code for this project is publicly available at GitHub.
Going Beyond Linear Mode Connectivity: The Layerwise Linear Feature Connectivity
Zhanpeng Zhou, Yongyi Yang, Xiaojiang Yang, Junchi Yan, Wei Hu
Abstract: Recent work has revealed many intriguing empirical phenomena in neural network training, despite the poorly understood and highly complex loss landscapes and training dynamics. One of these phenomena, Linear Mode Connectivity (LMC), has gained considerable attention due to the intriguing observation that different solutions can be connected by a linear path in the parameter space while maintaining near-constant training and test losses. In this work, we introduce a stronger notion of linear connectivity, Layerwise Linear Feature Connectivity (LLFC), which says that the feature maps of every layer in different trained networks are also linearly connected. We provide comprehensive empirical evidence for LLFC across a wide range of settings, demonstrating that whenever two trained networks satisfy LMC (via either spawning or permutation methods), they also satisfy LLFC in nearly all the layers. Furthermore, we delve deeper into the underlying factors contributing to LLFC, which reveal new insights into the spawning and permutation approaches. The study of LLFC transcends and advances our understanding of LMC by adopting a feature-learning perspective.
Towards A Richer 2D Understanding of Hands at Scale
Tianyi Cheng, Dandan Shan, Ayda Hassen, Richard Higgins, David Fouhey
Abstract: As humans, we learn a lot about how to interact with the world by observing others interacting with their hands. To help AI systems obtain a better understanding of hand interactions, we introduce a new model that produces a rich understanding of hand interaction. Our system produces a richer output than past systems at a larger scale. Our outputs include boxes and segments for hands, in-contact objects, and second objects touched by tools as well as contact and grasp type. Supporting this method are annotations of 257K images, 401K hands, 288K objects, and 19K second objects spanning four datasets. We show that our method provides rich information and performs and generalizes well.