
 MENU
MENU 

Personalized knowledge graphs for faster search and digital assistants
Graphs that are customized, stored locally, and able to change over time can enable faster and more accurate searching and digital assistants

 Enlarge
EnlargeAs collective knowledge grows, it becomes challenging for personal devices to sift through all that information and provide the answers that users want when they run a search or talk to their digital assistant.
Knowledge or facts are often stored in a structure called a knowledge graph. This collection of nodes and edges stores entities, concepts, and their relationships as a means to navigate large amounts of data. This representation is intuitive for making search queries and inferring knowledge, since these tasks require a way to view the connections between different concepts and things. In a way, it’s a very rudimentary digital brain.
Unfortunately these brains have gotten too big – knowledge graphs on the order of millions of entities and billions of relationships become harder and harder to efficiently search.
Prof. Danai Koutra has proposed a mobile solution to develop constantly-evolving, personalized knowledge bases that identify information that’s most relevant to the user’s changing interests. In her project “Adaptive Personalized Knowledge Graph Summarization,” Koutra and her collaborators are working to take on this shortcoming with graphs that are customized, stored locally, and able to change over time. Koutra earned an Amazon Research Award for the project.
The most relevant current research in knowledge graphs focuses on efficient information retrieval with the use of indices or on knowledge graph summarization to construct concise but comprehensive versions of an original. Neither of these methods are user-driven or flexible to changes in the data, however, which are two features that are important in the real world.
A personalized knowledge graph stored right on the user’s device, such as their smartphone, would mean both a huge performance boost and better personalization when interacting with different web services. Searches, voice assistant responses, and other tools would draw from a compact database of the user’s interests over time in order to produce more meaningful results faster.
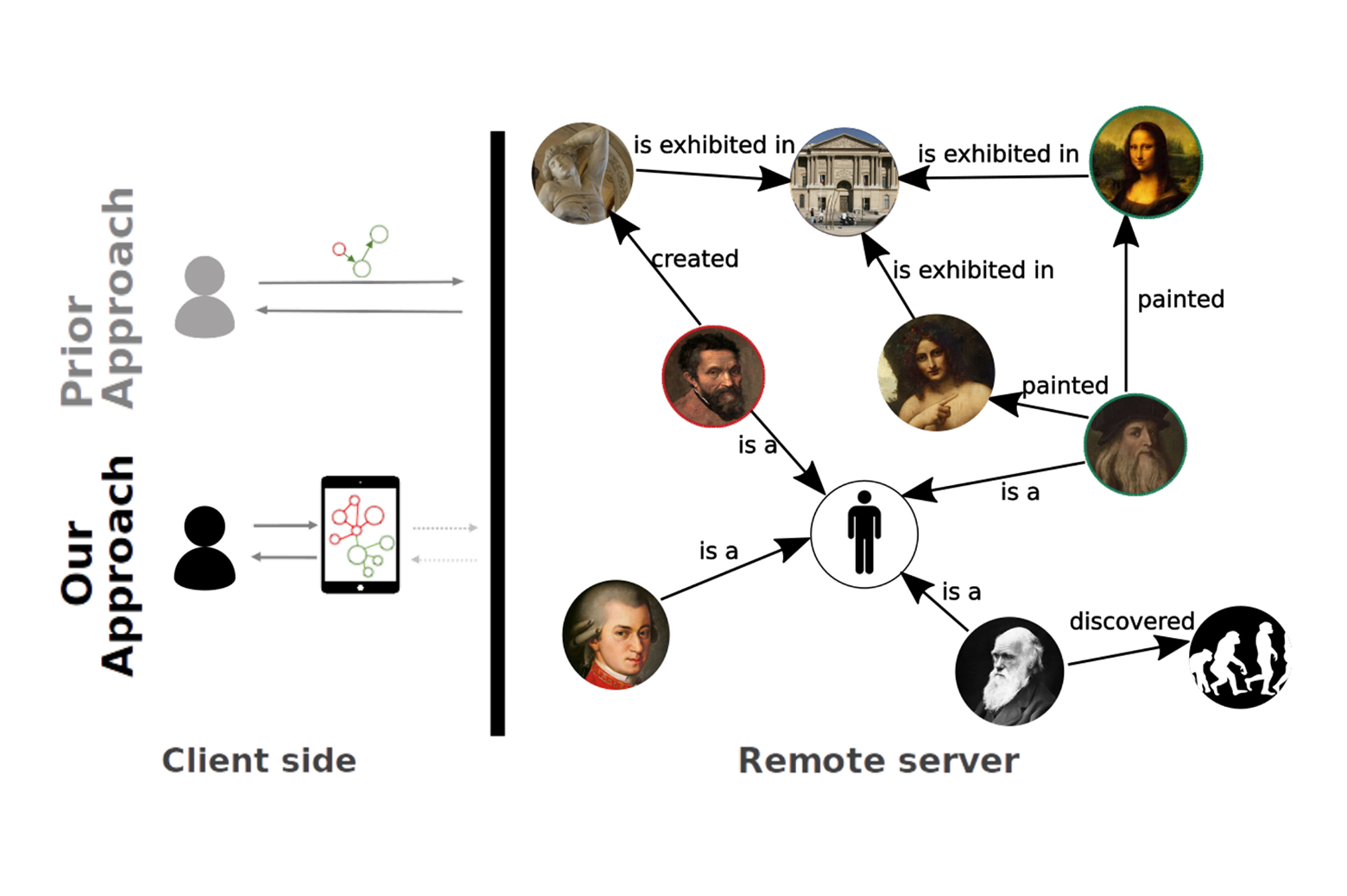 Enlarge
EnlargeIn order to make sure the user’s summarized knowledge graph has enough information to be useful, the team says it will have to fulfill three key traits: representation, personalization, and adaptation.
Representation means that a summarized version of a bigger knowledge graph needs to be accurate while still reduced in size enough to fit on the user’s device. Personalization is the need to make sure the information included in the summary reflects the user’s interests and past searches. Finally, the key to making this framework useful over time will be its adaptability – the more the user interacts with their phone’s services, the more the knowledge graph should be adjusted to meet their needs. The challenge here will be knowing not only what to include as the user’s interests continually evolve, but what to remove.
“Our position is that,” the researchers write in a project summary, “for massive graph datasets and in particular knowledge graphs that inherently serve different people in different ways, ‘one-size-fits-all’ graph summaries are less useful to users than adaptive, personalized summaries.”
Koutra and her collaborators believe the next frontier of graph summarization lies in personalized and incrementally adaptive techniques. Their future work in this direction will be a step toward efficient information access and knowledge discovery for all users, regardless of location or online connectivity.